The dreaded Thursday afternoon or Friday morning chore of fighting with the timesheet system. This has got to be the worst part of the weekly work experience, but without it, one doesn’t get paid.
I have tried many systems from pen and paper, to spreadsheets to online content management systems. For years I considered the timesheet exercise nothing but a big pain in the butt. What I didn’t realise was the timesheet could be my key performance indicator (KPI) system.
We have all worked on projects where the walls were plastered with A0 sheets strung together with project KPIs. So why not extend this data gathering and measurement for one’s own work? I decided that I could use the timesheet as a useful tool rather than just a nightmare exercise of trying to allocate hours to project codes that may or may not have hours left in them.
I started searching the worldwide web for a way to track time, was web-based for use across multiple devices with the data stored on the cloud. What I came across was Clockify, but I assume there may to others that perform the same.
My idea at the start was to just track time with ease and help me in transposing my time into my employer’s timesheet system. I not only wanted to track WBS codes and notes but track deliverable numbers that I could use at a later stage.
I will cover the following in this article:
- Track time online – using Clockify
- Export time entries into Microsoft Excel
- Extract time entries via Clockify API
- Manipulation of data into a timesheet based format
- Cover a few ways I diced up the data to extract deliverables and time spent
- Python code on my GitHub page
Online time tracking
Set up a free account to start tracking. It’s that easy. Clockify has a Chrome extension, but I just use the web interface, as I find it easier to make edits, and start an earlier task with a pre-populated description.
Clockify time entry has 5 main inputs:
- Description: I copy a pre-populated cell from a Project Tracking Workbook (discussed here) which has the Project number – WBS number – Deliverable number – notes. I paste it into the description and amend to suit.
- Project: Define under the Projects tab
- Tags: I don’t use. I find they are too administrative and cumbersome. I try to put everything I need into the description.
- $ Billable: Set up against the Project under the Projects tab
- Start/End times: Click on, click off per task.
Export the Time Entries to CSV or Excel File
Within Clockify web interface, export the time entries for selected dates as outlined.

Open up in your spreadsheet app of choice and manipulate the data into a timesheet format. I used Microsoft Excel’s Get & Transform Data (aka PowerQuery) to get into the following format. I won’t cover the transformation steps in this article as I have since abandoned this for the much easier Python API method.

Extract the Time Entries using Python and API
Clockify provides a REST-based API for which we can use Python to dial into the data. I will run through the items I found while searching around to get it to work. I’m sure the documentation is concise, but this was my first API request so I was learning.
The following are excerpts from my Python code, which I have included over on my GitHub page.
Import the required libraries
import pandas as pd
import numpy as np
import requests
from requests.exceptions import HTTPError
import json
import re
import configparser
from pathlib import Path Get and Response of Projects
Here are some call examples provided on Clockify API documentation page. Let’s put a few of these to use in our code.
API Base Endpoint: https://api.clockify.me/api/v1
Project: GET /workspaces/{workspaceId}/projects
Time entry:POST /workspaces/{workspaceId}/time-entriesGET /workspaces/{workspaceId}/time-entries/{id}PUT /workspaces/{workspaceId}/time-entries/{id}DELETE /workspaces/{workspaceId}/time-entries/{id}
# Note /user required at the end of the base endpoint
url_base = 'https://api.clockify.me/api/v1/user'
url = 'https://api.clockify.me/api/v1'
# https://docs.python.org/3/library/configparser.html
config = configparser.ConfigParser()
config.read('config.ini') # config.ini file with [clockify] and API_KEY = MyAPIKeyWithoutQuotes
X_Api_Key = config.get('clockify', 'API_KEY')
headers = {'content-type': 'application/json', 'X-Api-Key': X_Api_Key}
response = requests.get(url_base, headers=headers)
json_response_base = response.json()
json_response_base['id']
workspaceId = json_response_base['activeWorkspace']
userId = json_response_base['id']
api_projects = f'/workspaces/{workspaceId}/projects'
api_url = url + api_projects
response = requests.get(api_url, headers=headers)
json_response_projects = response.json()Now that we have retrieved our id and activeWorkspace we can get everything for each project defined in Clockify. The json response contains the following attributes which you populate via the web interface.
>> json_response_projects[0].keys()
dict_keys(['id', 'name', 'hourlyRate', 'clientId', 'workspaceId', 'billable', 'memberships', 'color', 'estimate', 'archived', 'duration', 'clientName', 'note', 'template', 'public']) Set Project and Dates
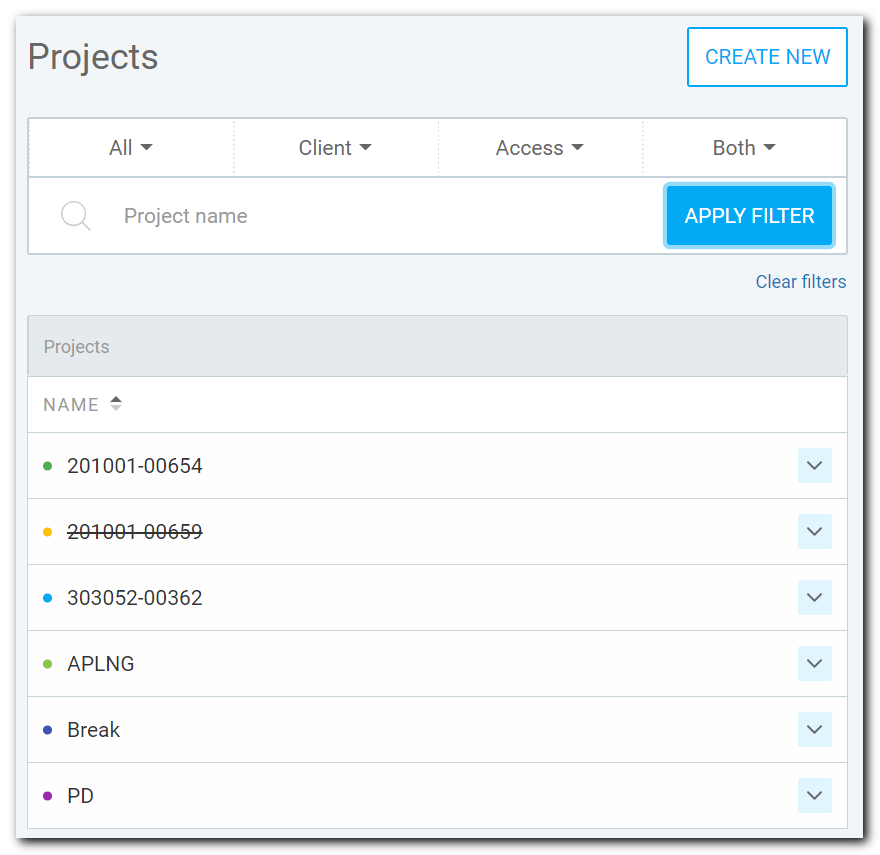
Here is a screenshot of the defined projects in the web interface.
# Print out a listing of projects
project_names = [i['name'] for i in json_response_projects]
print(f'Projects: {project_names}')
# STEP 1: Input the project of interest
project = project_names[3] # First one starts at zero.
print(f'Project selected: {project}')
projectId = [i['id'] for i in json_response_projects if i['name'] == project]
# STEP 2: Enter the start date of time sheet entries to retrieve
start_year = '2020'
start_month = '01'
start_day = '01'
# STEP 3: Parameter Inputs
params_num_of_entries_to_retrieve = 1000Projects: ['201001-00654', '201001-00659', '303052-00362', 'APLNG', 'Break', 'PD']
Project selected: APLNG The output of projects matches the web interface shown, which is an excellent sign.
Get and Response of Time Entries
With the desired project and dates, we make a request for the time entries.
start_utc = start_year + '-' + start_month + '-' + start_day + 'T00:00:00Z'
params={'start': start_utc, 'page-size' : params_num_of_entries_to_retrieve}
api_projects = f'/workspaces/{workspaceId}/projects'
api_time_entries = f'/workspaces/{workspaceId}/user/{userId}/time-entries'
api_url = url + api_time_entries
response = requests.get(api_url, headers=headers, params=params)
json_response_te = response.json() Here is a sample of the response.
>> json_response_te[1]
{'id': '....f7f8',
'description': 'WQA.18814 RE102025-1 WQA.18814-DD-00602_000_IFP Pipes and Fittings MTO.',
'tagIds': None,
'userId': '....e71d',
'billable': True,
'taskId': None,
'projectId': '....3795a',
'timeInterval': {'start': '2020-04-01T00:00:00Z',
'end': '2020-04-01T02:30:00Z',
'duration': 'PT2H30M'},
'workspaceId': '....fbf8',
'isLocked': False,
'customFieldValues': []}Clean the Data
The json response data type is a dictionary. To put this response into a panda dataframe can be done using DataFrame.from.dict().
This section is where I split out the description column into multiple columns of WBS, Deliverable number, etc. This is where I do my tagging, with better control and easier to carry out than the web-based tag interface.
df = pd.DataFrame.from_dict(json_response_te)
df = df[['description','billable','timeInterval']]
# Split out timeInterval dict to values as the most efficient way.
# https://stackoverflow.com/questions/38231591
df = pd.concat([df.drop('timeInterval', axis=1), pd.DataFrame(df['timeInterval'].values.tolist())], axis=1)
# Convert from object to datetime
df['start'] = pd.to_datetime(df['start'])
df['end'] = pd.to_datetime(df['end'])
df['WBS'] = df['description'].str.extract(r'(\S+)')
df['WQA_No'] = df['description'].str.extract(r'(WQA.\d{5})')
df['RE_No'] = df['description'].str.extract(r'(RE\d{5}[\w]+)')
df['Doc_No'] = df['description'].str.extract(r'(WQA.\d{5}-\w{2}-\d{5})')
df['VDN_No'] = df['description'].str.extract(r'(\d{10}-\w{4}-\d{4})')
df['Doc_No'] = df['Doc_No'].fillna(df['VDN_No'])
df['Short_Desc'] = df['description'].apply(lambda x: fn_strip_out_codes_from_text(x))
# `dt` accessor used per https://stackoverflow.com/questions/34789888
df['start'] = df['start'].dt.tz_convert(local_tz)
df['end'] = df['end'].dt.tz_convert(local_tz)
df['duration'] = df['end'] - df['start']
df['duration_hours'] = df['duration'].dt.total_seconds() / 60 / 60
df['duration_round'] = round(df['duration'].dt.total_seconds() / 60 / 60 * 2) / 2
# https://docs.python.org/3/library/datetime.html
df['day'] = df['start'].dt.strftime('%a')
df['dayno'] = df['start'].dt.strftime('%w').astype('int')
df['week'] = df['start'].dt.strftime('%W').astype('int')
df.fillna('', inplace=True)Dateframe sample output:
>> df.loc[1]
description WQA.18814 RE102025-1 WQA.18814-DD-00602_000_IFP Pipes and Fittings MTO.
billable True
start 2020-04-01 10:00:00+10:00
end 2020-04-01 12:30:00+10:00
duration 0 days 02:30:00
WBS WQA.18814
WQA_No WQA.18814
RE_No RE102025
Doc_No WQA.18814-DD-00602
VDN_No
Short_Desc Pipes and Fittings MTO.
duration_hours 2.50
duration_round 2.50
day Wed
dayno 3
week 13
Name: 1, dtype: objectThe more interesting column is the Short_Desc. Since I sliced up the description data into columns, I didn’t want it repeating itself again just to see the note at the end.
What I wanted was some kind of inverse negative regular expression match. With the help of StackOverflow, I created a function to strip out everything that I extracted before and keep what hadn’t, or the note at the end.
def fn_strip_out_codes_from_text(string_with_codes):
"""Strip out regular expression text (codes) and return the rest.
Add a column by applying this function with lambda
df['new'] = df['col_with_codes'].apply(lambda x: functionname(x))
"""
# https://stackoverflow.com/questions/44140794/python-regex-inverse-negative-match-on-a-single-line-not-on-multiple-lines-not
qw = string_with_codes
rx1 = r'WQA.[a-zA-Z0-9.\-\_]+|((?:(?!WQA.[a-zA-Z0-9.\-\_]+)\S)+)'
result1 = re.findall(rx1, qw)
rx2 = r'RE[a-zA-Z0-9.\-\_]+|((?:(?!RE[a-zA-Z0-9.\-\_]+)\S)+)'
result2 = re.findall(rx2, ' '.join(str(word) for word in result1) )
result2 = ' '.join(str(word) for word in result2).strip().replace(' ', ' ')
return result2Analysis
Week Filtered
Pandas crosstab flips the data into a timesheet format with far fewer steps than Excel’s Get & Transform.
# Specify the ISO week number
week_no = 11
df_ts = df.loc[(df['billable'] == True) & (df['week'] == week_no)]
print(df_ts['end'].max().strftime('Week ending: %Y-%m-%d %a'))
def fn_crosstab_timesheet(df):
return pd.crosstab(df['wbs'], [df['dayno'], df['day']], values=df['duration_hours'], aggfunc='sum',margins=True)
fn_crosstab_timesheet(df_ts)
fn_crosstab_timesheet(df_ts).to_clipboard()
display(fn_crosstab_timesheet(df_ts))
display(fn_crosstab_timesheet(df_ts, rounded=False))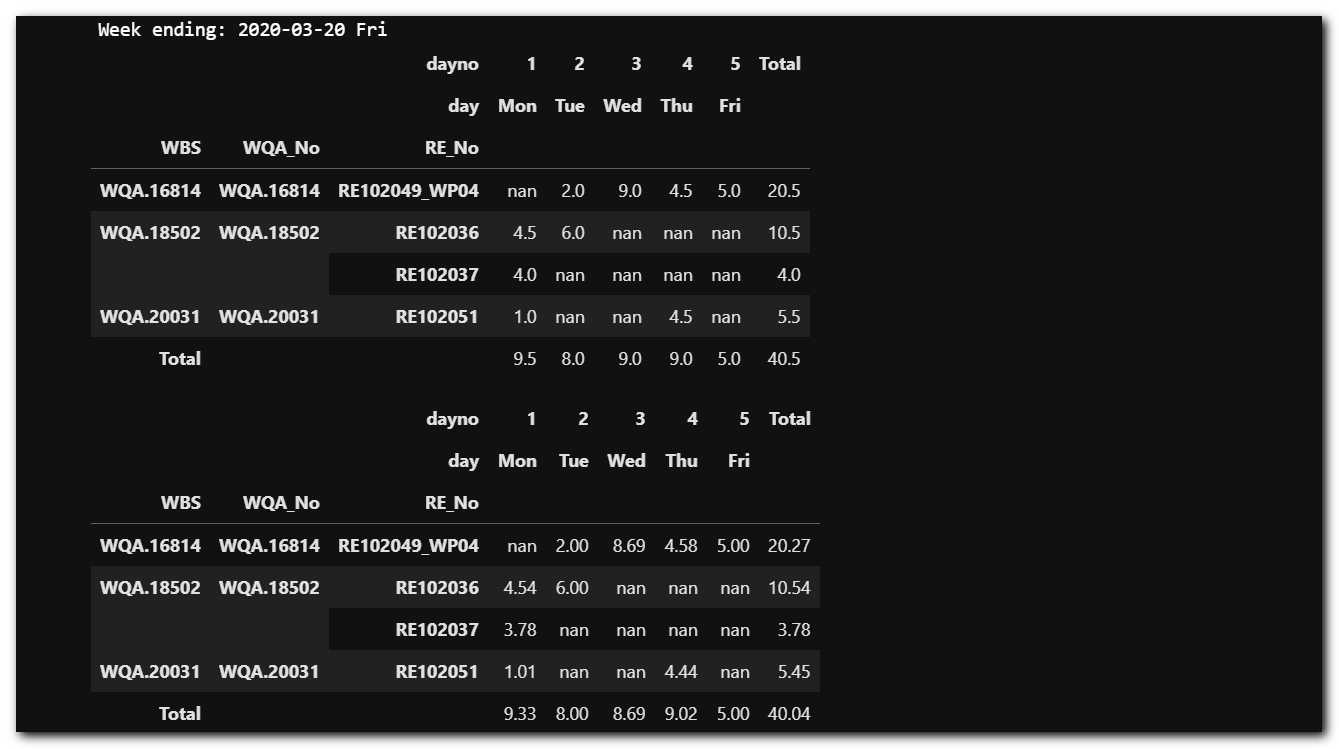
I displayed both rounded and exact hours, as the rounded matches the timesheet system requirements, but during the rounding operation you have to check the exact hours for adjustments.
Week Filtered – Details
This provides a snapshot of the activities performed for the week.
print(df_ts['end'].max().strftime('Week ending: %Y-%m-%d %a'))
agg_gb = {'duration_round': 'sum'}
pd.pivot_table(df_ts, index=['WBS', 'Doc_No','Short_Desc'], aggfunc=agg_gb, values=['duration_round'],
margins=True, margins_name='TOTAL HOURS')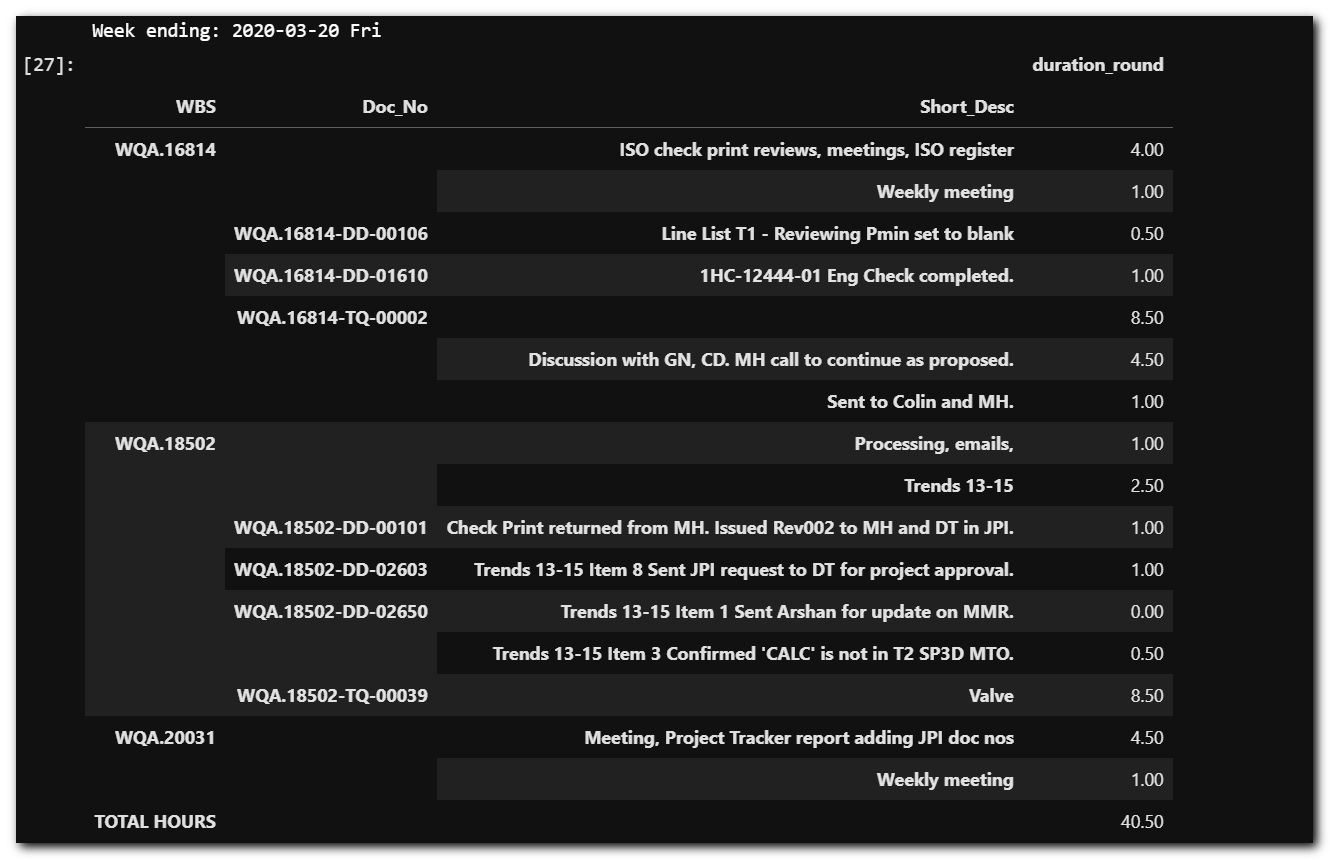
Description Filter
A common task is searching for something to find a summary of hours and any notes. I just ran a pivot_table searching on the description column. any_words is a boolean to either True, that any of the words are matched or False with matches all search words.
search_words = ['WQA.16814', 'line', 'list']
agg_gb = {'duration_round': 'sum', 'start': 'min', 'end': 'max'}
# any_words: False equals all words (AND), True equals any of the words (OR)
pd.pivot_table(mf.fn_filter_words_in_column(df, 'description', search_words, any_words=False),
index=['week', 'WBS', 'Doc_No','Short_Desc'], aggfunc=agg_gb, values=agg_gb.keys(),
margins=True, margins_name='TOTAL HOURS')
Here is the filter function which I keep in myfunct.py file.
def fn_filter_words_in_column(df, col_to_search, search_words, any_words=True):
"""Filter for any (default) or all words in a dataframe column. Case insensitive.
df: dataframe to search
col_to_search: column name to search as a str
search_words: list of search words
any_words: Default True to search for any word. False will search to match all words.
"""
if any_words == True:
df_f = df.loc[df[col_to_search].str.lower().apply(
lambda x: any(word.lower() in x for word in search_words))]
else:
df_f = df.loc[df[col_to_search].str.lower().apply(
lambda x: all(word.lower() in x for word in search_words))]
return df_fDiscussion
This was my first crack at APIs using Python and I’m sure the code is amateurish, but for now it does the trick and has many fewer ‘steps’ than my original Excel spreadsheet.
I need to further develop the KPI part of this timesheet exercise. Since I have the data and toolbox set up, it should be easy to add other elements.
For example, in the SANDBOX section of the code I grouped documents and their durations. I could split out the document numbers and group by deliverable attributes to improve reporting and use for future engineering estimates.
I haven’t covered the APIs post, put or delete as I haven’t yet found a need. The post or adding entries using the web interface is slick and easy. I haven’t needed to delete any entries and don’t know the difference between put and post. If I ever find a use for these, I will update this post.
As always, if you have any comments, queries or suggestions, please drop them in the comments.